Landscape Analysis¶
Load in Raw Data¶
Go through each record, load in supporting objects, flatten everything into records, and put into a massive dataframe.
[1]:
import recirq
import cirq
import numpy as np
import pandas as pd
from datetime import datetime
from recirq.qaoa.experiments.p1_landscape_tasks import \
DEFAULT_BASE_DIR, DEFAULT_PROBLEM_GENERATION_BASE_DIR, DEFAULT_PRECOMPUTATION_BASE_DIR, \
ReadoutCalibrationTask
records = []
ro_records = []
for record in recirq.iterload_records(dataset_id="2020-03-tutorial", base_dir=DEFAULT_BASE_DIR):
record['timestamp'] = datetime.fromisoformat(record['timestamp'])
dc_task = record['task']
if isinstance(dc_task, ReadoutCalibrationTask):
ro_records.append(record)
continue
pgen_task = dc_task.generation_task
problem = recirq.load(pgen_task, base_dir=DEFAULT_PROBLEM_GENERATION_BASE_DIR)['problem']
record['problem'] = problem.graph
record['problem_type'] = problem.__class__.__name__
record['bitstrings'] = record['bitstrings'].bits
recirq.flatten_dataclass_into_record(record, 'task')
recirq.flatten_dataclass_into_record(record, 'generation_task')
records.append(record)
# Associate each data collection task with its nearest readout calibration
for record in sorted(records, key=lambda x: x['timestamp']):
record['ro'] = min(ro_records, key=lambda x: abs((x['timestamp']-record['timestamp']).total_seconds()))
df_raw = pd.DataFrame(records)
df_raw.head()
[1]:
| timestamp | bitstrings | qubits | final_qubits | execution_time | problem | problem_type | dataset_id | device_name | n_shots | gamma | beta | line_placement_strategy | generation_task.dataset_id | instance_i | n_qubits | ro | generation_task.device_name | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2020-05-16 18:39:09.140680 | [[1, 0, 0], [1, 0, 1], [0, 0, 1], [0, 0, 0], [... | [(4, 1), (4, 2), (3, 2)] | [(3, 2), (4, 2), (4, 1)] | 0.234015 | (0, 1, 2) | SKProblem | 2020-03-tutorial | Syc23-simulator | 50000 | 0.628319 | -0.157080 | None | 2020-03-tutorial | 0 | 3 | {'timestamp': 2020-05-16 18:38:45.218225, 'tas... | NaN |
| 1 | 2020-05-16 18:40:53.197716 | [[1, 0, 1], [0, 0, 1], [1, 0, 0], [1, 1, 0], [... | [(4, 1), (4, 2), (3, 2)] | [(3, 2), (4, 2), (4, 1)] | 0.244440 | (0, 1, 2) | SKProblem | 2020-03-tutorial | Syc23-simulator | 50000 | 1.570796 | 0.785398 | None | 2020-03-tutorial | 0 | 3 | {'timestamp': 2020-05-16 18:40:46.466873, 'tas... | NaN |
| 2 | 2020-05-16 18:38:54.274562 | [[0, 0, 1], [0, 1, 0], [1, 1, 1], [0, 0, 1], [... | [(4, 1), (4, 2), (3, 2)] | [(3, 2), (4, 2), (4, 1)] | 0.333645 | (0, 1, 2) | SKProblem | 2020-03-tutorial | Syc23-simulator | 50000 | 1.099557 | -0.157080 | None | 2020-03-tutorial | 0 | 3 | {'timestamp': 2020-05-16 18:38:45.218225, 'tas... | NaN |
| 3 | 2020-05-16 18:40:52.750232 | [[1, 0, 1], [0, 1, 0], [1, 0, 1], [0, 1, 0], [... | [(4, 1), (4, 2), (3, 2)] | [(3, 2), (4, 2), (4, 1)] | 0.303454 | (0, 1, 2) | SKProblem | 2020-03-tutorial | Syc23-simulator | 50000 | 0.000000 | -0.628319 | None | 2020-03-tutorial | 0 | 3 | {'timestamp': 2020-05-16 18:40:46.466873, 'tas... | NaN |
| 4 | 2020-05-16 18:40:54.116035 | [[1, 1, 1], [1, 0, 1], [0, 0, 0], [1, 1, 0], [... | [(4, 1), (4, 2), (3, 2)] | [(3, 2), (4, 2), (4, 1)] | 0.227513 | (0, 1, 2) | SKProblem | 2020-03-tutorial | Syc23-simulator | 50000 | 0.942478 | 0.628319 | None | 2020-03-tutorial | 0 | 3 | {'timestamp': 2020-05-16 18:40:46.466873, 'tas... | NaN |
Narrow down to Relevant Data¶
Drop unnecessary metadata and use bitstrings to compute the expected value of the energy. In general, it’s better to save the raw data and lots of metadata so we can use it if it becomes necessary in the future.
[2]:
from recirq.qaoa.simulation import hamiltonian_objectives
def compute_energies(row):
permutation = []
qubit_map = {}
for i, q in enumerate(row['qubits']):
fi = row['final_qubits'].index(q)
permutation.append(fi)
qubit_map[i] = q
return hamiltonian_objectives(row['bitstrings'],
row['problem'],
permutation,
row['ro']['calibration'],
qubit_map)
# Start cleaning up the raw data
df = df_raw.copy()
df = df.drop(['line_placement_strategy',
'generation_task.dataset_id',
'generation_task.device_name'], axis=1)
# Compute energies
df['energies'] = df.apply(compute_energies, axis=1)
df = df.drop(['bitstrings', 'problem', 'ro', 'qubits', 'final_qubits'], axis=1)
df['energy'] = df.apply(lambda row: np.mean(row['energies']), axis=1)
# We won't do anything with raw energies right now
df = df.drop('energies', axis=1)
# Do timing somewhere else
df = df.drop([col for col in df.columns if col.endswith('_time')], axis=1)
df
[2]:
| timestamp | problem_type | dataset_id | device_name | n_shots | gamma | beta | instance_i | n_qubits | energy | |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2020-05-16 18:39:09.140680 | SKProblem | 2020-03-tutorial | Syc23-simulator | 50000 | 0.628319 | -0.157080 | 0 | 3 | -0.226636 |
| 1 | 2020-05-16 18:40:53.197716 | SKProblem | 2020-03-tutorial | Syc23-simulator | 50000 | 1.570796 | 0.785398 | 0 | 3 | 0.004430 |
| 2 | 2020-05-16 18:38:54.274562 | SKProblem | 2020-03-tutorial | Syc23-simulator | 50000 | 1.099557 | -0.157080 | 0 | 3 | 0.812318 |
| 3 | 2020-05-16 18:40:52.750232 | SKProblem | 2020-03-tutorial | Syc23-simulator | 50000 | 0.000000 | -0.628319 | 0 | 3 | 0.004591 |
| 4 | 2020-05-16 18:40:54.116035 | SKProblem | 2020-03-tutorial | Syc23-simulator | 50000 | 0.942478 | 0.628319 | 0 | 3 | 1.369136 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 358 | 2020-05-16 18:48:30.402142 | ThreeRegularProblem | 2020-03-tutorial | Syc23-simulator | 50000 | 0.314159 | -0.785398 | 0 | 4 | 1.538373 |
| 359 | 2020-05-16 18:50:13.035131 | ThreeRegularProblem | 2020-03-tutorial | Syc23-simulator | 50000 | 0.628319 | 0.785398 | 0 | 4 | 0.568978 |
| 360 | 2020-05-16 18:45:00.639575 | ThreeRegularProblem | 2020-03-tutorial | Syc23-simulator | 50000 | 1.413717 | 0.000000 | 0 | 4 | -0.026658 |
| 361 | 2020-05-16 18:44:46.659427 | ThreeRegularProblem | 2020-03-tutorial | Syc23-simulator | 50000 | 0.628319 | 0.157080 | 0 | 4 | 0.273670 |
| 362 | 2020-05-16 18:48:14.641629 | ThreeRegularProblem | 2020-03-tutorial | Syc23-simulator | 50000 | 1.413717 | 0.157080 | 0 | 4 | 0.707080 |
363 rows × 10 columns
Compute theoretical landscape¶
Use a simulator to compute the noiseless landscape. This can get quite expensive, so it would be better practice to factor this out into Tasks in their own right: https://github.com/quantumlib/ReCirq/issues/21
[3]:
def get_problem_graph(problem_type,
n=None,
instance_i=0):
if n is None:
if problem_type == 'HardwareGridProblem':
n = 4
elif problem_type == 'SKProblem':
n = 3
elif problem_type == 'ThreeRegularProblem':
n = 4
else:
raise ValueError(repr(problem_type))
r = df_raw[
(df_raw['problem_type']==problem_type)&
(df_raw['n_qubits']==n)&
(df_raw['instance_i']==instance_i)
]['problem']
return r.iloc[0]
from recirq.qaoa.simulation import exact_qaoa_values_on_grid, lowest_and_highest_energy
import itertools
def compute_exact_values(problem_type, x_grid_num=23, y_grid_num=21):
exact = exact_qaoa_values_on_grid(
graph=get_problem_graph(problem_type),
num_processors=12,
x_grid_num=x_grid_num,
y_grid_num=y_grid_num,
).T.reshape(-1)
exact_gammas = np.linspace(0, np.pi/2, x_grid_num)
exact_betas = np.linspace(-np.pi/4, np.pi/4, y_grid_num)
exact_points = np.asarray(list(itertools.product(exact_gammas, exact_betas)))
min_c, max_c = lowest_and_highest_energy(get_problem_graph(problem_type))
return exact_points, exact, min_c, max_c
EXACT_VALS_CACHE = {k: compute_exact_values(k)
for k in ['HardwareGridProblem', 'SKProblem', 'ThreeRegularProblem']}
Plot¶
[4]:
%matplotlib inline
from matplotlib import pyplot as plt
import seaborn as sns
sns.set_style('ticks')
plt.rc('axes', labelsize=16, titlesize=16)
plt.rc('xtick', labelsize=14)
plt.rc('ytick', labelsize=14)
plt.rc('legend', fontsize=14, title_fontsize=16)
# Note: I ran into https://github.com/matplotlib/matplotlib/issues/15410
# if I imported matplotlib before using multiprocessing in `exact_qaoa_values_on_grid`, YMMV.
[5]:
import scipy.interpolate
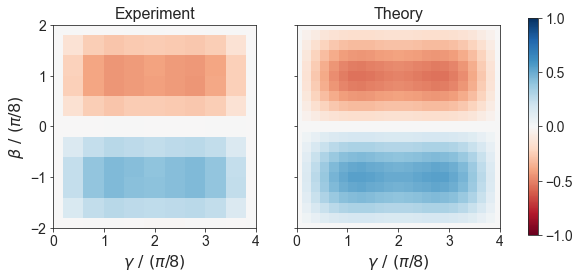
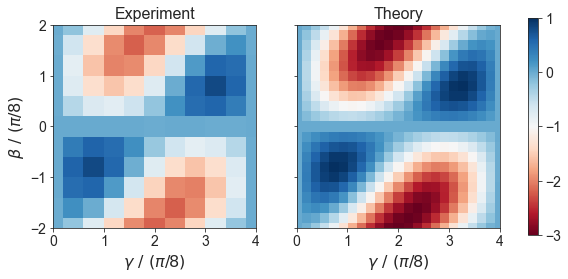
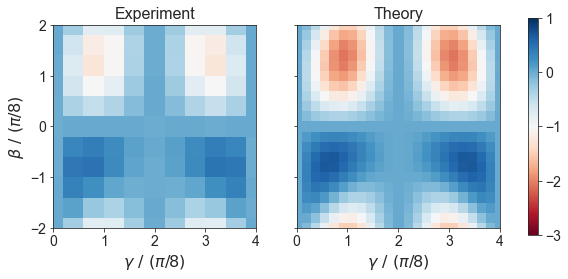
def plot_landscape(problem_type, res=200, method='nearest', cmap='PuOr'):
dfb = df
dfb = dfb[dfb['problem_type'] == problem_type]
xx, yy = np.meshgrid(np.linspace(0, np.pi/2, res), np.linspace(-np.pi/4, np.pi/4, res))
exact_points, exact, min_c, max_c = EXACT_VALS_CACHE[problem_type]
zz = scipy.interpolate.griddata(
points=dfb[['gamma', 'beta']].values,
values=dfb['energy'].values / min_c,
xi=(xx, yy),
method=method,
)
fig, (axl, axr) = plt.subplots(1, 2, figsize=(5*2, 5), sharey=True)
norm = plt.Normalize(max_c/min_c, min_c/min_c)
cmap = 'RdBu'
extent=(0, 4, -2, 2)
axl.imshow(zz, extent=extent, origin='lower', cmap=cmap, norm=norm, interpolation='none')
axl.set_xlabel(r'$\gamma\ /\ (\pi/8)$')
axl.set_ylabel(r'$\beta\ /\ (\pi/8)$')
axl.set_title('Experiment')
zz_exact = scipy.interpolate.griddata(
points=exact_points,
values=(exact/min_c),
xi=(xx, yy),
method=method,
)
g = axr.imshow(zz_exact, extent=extent, origin='lower', cmap=cmap, norm=norm, interpolation='none')
axr.set_xlabel(r'$\gamma\ /\ (\pi/8)$')
axr.set_title('Theory')
fig.colorbar(g, ax=[axl, axr], shrink=0.8)